搜索到
7
篇与
的结果
-
 七、pandas - 数据分析 - 案例 (1)企鹅体重分析# 1. 导入相关库 import numpy as np import pandas as pd # 2. 导入数据 df = pd.read_csv('static/2_pandas/data/penguins.csv') print(df.head(10)) species island bill_length_mm bill_depth_mm flipper_length_mm \ 0 Adelie Torgersen 39.1 18.7 181.0 1 Adelie Torgersen 39.5 17.4 186.0 2 Adelie Torgersen 40.3 18.0 195.0 3 Adelie Torgersen NaN NaN NaN 4 Adelie Torgersen 36.7 19.3 193.0 5 Adelie Torgersen 39.3 20.6 190.0 6 Adelie Torgersen 38.9 17.8 181.0 7 Adelie Torgersen 39.2 19.6 195.0 8 Adelie Torgersen 34.1 18.1 193.0 9 Adelie Torgersen 42.0 20.2 190.0 body_mass_g sex 0 3750.0 Male 1 3800.0 Female 2 3250.0 Female 3 NaN NaN 4 3450.0 Female 5 3650.0 Male 6 3625.0 Female 7 4675.0 Male 8 3475.0 NaN 9 4250.0 NaN # 3. 数据清洗 # 处理缺失值 df.dropna(inplace=True) # 4. 构造数据特征 df['sex'] = df['sex'].astype('category') df['bill_ratio'] = df['bill_length_mm'] / df['bill_depth_mm'] # print(df.head(10)) # 5. 数据分析 # 数据分箱 - 体重:低、中、高 labels = ['低', '中', '高'] df['mass_level'] = pd.cut(df['body_mass_g'], bins=3, labels=labels) print(df['mass_level'].value_counts()) print() # 按岛屿、性别分组 print(df.groupby(['island', 'sex'], observed=False).agg({ 'body_mass_g': ['mean', 'count'] })) mass_level 低 150 中 128 高 55 Name: count, dtype: int64 body_mass_g mean count island sex Biscoe Female 4319.375000 80 Male 5104.518072 83 Dream Female 3446.311475 61 Male 3987.096774 62 Torgersen Female 3395.833333 24 Male 4034.782609 23(2)睡眠质量分析import numpy as np import pandas as pd # 导入数据 df = pd.read_csv('static/2_pandas/data/sleep.csv') print(df.head(10)) person_id gender age occupation sleep_duration sleep_quality \ 0 1 Male 29 Manual Labor 7.4 7.0 1 2 Female 43 Retired 4.2 4.9 2 3 Male 44 Retired 6.1 6.0 3 4 Male 29 Office Worker 8.3 10.0 4 5 Male 67 Retired 9.1 9.5 5 6 Female 47 Student 6.1 6.9 6 7 Male 22 Office Worker 5.1 6.1 7 8 Male 49 Office Worker 10.7 6.2 8 9 Male 25 Manual Labor 11.9 7.2 9 10 Female 51 Retired 8.2 4.0 physical_activity_level stress_level bmi_category blood_pressure \ 0 41 7 Obese 124/70 1 41 5 Obese 131/86 2 107 4 Underweight 122/70 3 20 10 Obese 124/72 4 19 4 Overweight 133/78 5 24 4 Normal 123/60 6 26 6 Obese 121/70 7 49 8 Obese 134/87 8 27 8 Underweight 112/63 9 64 5 Overweight 125/84 heart_rate daily_steps sleep_disorder 0 91 8539 NaN 1 81 18754 NaN 2 81 2857 NaN 3 55 6886 NaN 4 97 14945 Insomnia 5 87 9485 NaN 6 66 15680 NaN 7 59 18767 NaN 8 99 16397 Sleep Apnea 9 76 12744 NaN # 数据清洗 # 处理缺失值 df.fillna({"sleep_disorder": "unknown"}, inplace=True) # print(df.head(10)) # 构造数据特征 df['gender'] = df['gender'].astype('category') df['occupation'] = df['occupation'].astype('category') df['bmi_category'] = df['bmi_category'].astype('category') df[['high_pressure', 'low_pressure']] = df['blood_pressure'].str.split('/', expand=True) # df.info() # 睡眠质量分箱 labels = ['差', '良', '优'] df['sleep_quality_level'] = pd.cut(df['sleep_quality'], bins=3, labels=labels) print(df.head(3)) person_id gender age occupation sleep_duration sleep_quality \ 0 1 Male 29 Manual Labor 7.4 7.0 1 2 Female 43 Retired 4.2 4.9 2 3 Male 44 Retired 6.1 6.0 physical_activity_level stress_level bmi_category blood_pressure \ 0 41 7 Obese 124/70 1 41 5 Obese 131/86 2 107 4 Underweight 122/70 heart_rate daily_steps sleep_disorder high_pressure low_pressure \ 0 91 8539 unknown 124 70 1 81 18754 unknown 131 86 2 81 2857 unknown 122 70 sleep_quality_level 0 良 1 良 2 良 # 数据分析 print(df['bmi_category'].value_counts()) bmi_category Overweight 109 Underweight 102 Obese 98 Normal 91 Name: count, dtype: int64# 根据bmi分组 bmi_group = df.groupby('bmi_category', observed=True).agg({ 'sleep_duration': 'mean', 'sleep_quality': 'mean', 'stress_level': 'mean' }) print(bmi_group) sleep_duration sleep_quality stress_level bmi_category Normal 7.794505 6.342857 4.857143 Obese 8.072449 6.189796 5.765306 Overweight 8.274312 6.101835 5.642202 Underweight 7.982353 5.896078 5.558824
七、pandas - 数据分析 - 案例 (1)企鹅体重分析# 1. 导入相关库 import numpy as np import pandas as pd # 2. 导入数据 df = pd.read_csv('static/2_pandas/data/penguins.csv') print(df.head(10)) species island bill_length_mm bill_depth_mm flipper_length_mm \ 0 Adelie Torgersen 39.1 18.7 181.0 1 Adelie Torgersen 39.5 17.4 186.0 2 Adelie Torgersen 40.3 18.0 195.0 3 Adelie Torgersen NaN NaN NaN 4 Adelie Torgersen 36.7 19.3 193.0 5 Adelie Torgersen 39.3 20.6 190.0 6 Adelie Torgersen 38.9 17.8 181.0 7 Adelie Torgersen 39.2 19.6 195.0 8 Adelie Torgersen 34.1 18.1 193.0 9 Adelie Torgersen 42.0 20.2 190.0 body_mass_g sex 0 3750.0 Male 1 3800.0 Female 2 3250.0 Female 3 NaN NaN 4 3450.0 Female 5 3650.0 Male 6 3625.0 Female 7 4675.0 Male 8 3475.0 NaN 9 4250.0 NaN # 3. 数据清洗 # 处理缺失值 df.dropna(inplace=True) # 4. 构造数据特征 df['sex'] = df['sex'].astype('category') df['bill_ratio'] = df['bill_length_mm'] / df['bill_depth_mm'] # print(df.head(10)) # 5. 数据分析 # 数据分箱 - 体重:低、中、高 labels = ['低', '中', '高'] df['mass_level'] = pd.cut(df['body_mass_g'], bins=3, labels=labels) print(df['mass_level'].value_counts()) print() # 按岛屿、性别分组 print(df.groupby(['island', 'sex'], observed=False).agg({ 'body_mass_g': ['mean', 'count'] })) mass_level 低 150 中 128 高 55 Name: count, dtype: int64 body_mass_g mean count island sex Biscoe Female 4319.375000 80 Male 5104.518072 83 Dream Female 3446.311475 61 Male 3987.096774 62 Torgersen Female 3395.833333 24 Male 4034.782609 23(2)睡眠质量分析import numpy as np import pandas as pd # 导入数据 df = pd.read_csv('static/2_pandas/data/sleep.csv') print(df.head(10)) person_id gender age occupation sleep_duration sleep_quality \ 0 1 Male 29 Manual Labor 7.4 7.0 1 2 Female 43 Retired 4.2 4.9 2 3 Male 44 Retired 6.1 6.0 3 4 Male 29 Office Worker 8.3 10.0 4 5 Male 67 Retired 9.1 9.5 5 6 Female 47 Student 6.1 6.9 6 7 Male 22 Office Worker 5.1 6.1 7 8 Male 49 Office Worker 10.7 6.2 8 9 Male 25 Manual Labor 11.9 7.2 9 10 Female 51 Retired 8.2 4.0 physical_activity_level stress_level bmi_category blood_pressure \ 0 41 7 Obese 124/70 1 41 5 Obese 131/86 2 107 4 Underweight 122/70 3 20 10 Obese 124/72 4 19 4 Overweight 133/78 5 24 4 Normal 123/60 6 26 6 Obese 121/70 7 49 8 Obese 134/87 8 27 8 Underweight 112/63 9 64 5 Overweight 125/84 heart_rate daily_steps sleep_disorder 0 91 8539 NaN 1 81 18754 NaN 2 81 2857 NaN 3 55 6886 NaN 4 97 14945 Insomnia 5 87 9485 NaN 6 66 15680 NaN 7 59 18767 NaN 8 99 16397 Sleep Apnea 9 76 12744 NaN # 数据清洗 # 处理缺失值 df.fillna({"sleep_disorder": "unknown"}, inplace=True) # print(df.head(10)) # 构造数据特征 df['gender'] = df['gender'].astype('category') df['occupation'] = df['occupation'].astype('category') df['bmi_category'] = df['bmi_category'].astype('category') df[['high_pressure', 'low_pressure']] = df['blood_pressure'].str.split('/', expand=True) # df.info() # 睡眠质量分箱 labels = ['差', '良', '优'] df['sleep_quality_level'] = pd.cut(df['sleep_quality'], bins=3, labels=labels) print(df.head(3)) person_id gender age occupation sleep_duration sleep_quality \ 0 1 Male 29 Manual Labor 7.4 7.0 1 2 Female 43 Retired 4.2 4.9 2 3 Male 44 Retired 6.1 6.0 physical_activity_level stress_level bmi_category blood_pressure \ 0 41 7 Obese 124/70 1 41 5 Obese 131/86 2 107 4 Underweight 122/70 heart_rate daily_steps sleep_disorder high_pressure low_pressure \ 0 91 8539 unknown 124 70 1 81 18754 unknown 131 86 2 81 2857 unknown 122 70 sleep_quality_level 0 良 1 良 2 良 # 数据分析 print(df['bmi_category'].value_counts()) bmi_category Overweight 109 Underweight 102 Obese 98 Normal 91 Name: count, dtype: int64# 根据bmi分组 bmi_group = df.groupby('bmi_category', observed=True).agg({ 'sleep_duration': 'mean', 'sleep_quality': 'mean', 'stress_level': 'mean' }) print(bmi_group) sleep_duration sleep_quality stress_level bmi_category Normal 7.794505 6.342857 4.857143 Obese 8.072449 6.189796 5.765306 Overweight 8.274312 6.101835 5.642202 Underweight 7.982353 5.896078 5.558824 -
六、pandas - 数据分析 演示数据:data.zip1. 数据的导入导出import pandas as pd # 导入数据 # csv df = pd.read_csv('static/2_pandas/data/employees.csv') print(df.salary.sum()) 691400.0# 导出 df = df.head() df.to_csv('static/2_pandas/data/employees1.csv')# json df_json = pd.read_json('static/2_pandas/data/data1.json') print(df_json) id name age 0 1 张三 25 1 2 李四 30 2 3 王五 28import json # 复杂json with open('static/2_pandas/data/test.json', encoding='utf-8') as f: data = json.load(f) print(type(data)) print(data['users']) print() df_json2 = pd.DataFrame(data['users']) print(df_json2) <class 'dict'> [{'id': 1, 'name': '张三', 'age': 28, 'email': 'zhangsan@example.com', 'is_active': True, 'join_date': '2022-03-15'}, {'id': 2, 'name': '李四', 'age': 35, 'email': 'lisi@example.com', 'is_active': False, 'join_date': '2021-11-02'}, {'id': 3, 'name': '王五', 'age': 24, 'email': 'wangwu@example.com', 'is_active': True, 'join_date': '2023-01-20'}] id name age email is_active join_date 0 1 张三 28 zhangsan@example.com True 2022-03-15 1 2 李四 35 lisi@example.com False 2021-11-02 2 3 王五 24 wangwu@example.com True 2023-01-202. 缺失值的处理import numpy as np import pandas as pd # 缺失值的处理 df = pd.DataFrame([[1, 2, pd.NA], ['A', None, 'D'], [7, 8, 9]], columns=['A', 'B', 'C']) print(df) print() # 检查元素是否是缺失值 print(df.isna()) print(df.isnull()) print() # 计算缺失值个数 # print(df.isna().sum()) # 列 print(df.isna().sum(axis=1)) # 行 A B C 0 1 2.0 <NA> 1 A NaN D 2 7 8.0 9 A B C 0 False False True 1 False True False 2 False False False A B C 0 False False True 1 False True False 2 False False False 0 1 1 1 2 0 dtype: int64# 剔除缺失值 # 剔除包含缺失值的行记录 print(df.dropna()) print() # 当前行的元素都为缺失值时才剔除 print(df.dropna(how='all')) print() # 如果有n个元素不是缺失值,则保留 print(df.dropna(thresh=2)) print() A B C 2 7 8.0 9 A B C 0 1 2.0 <NA> 1 A NaN D 2 7 8.0 9 A B C 0 1 2.0 <NA> 1 A NaN D 2 7 8.0 9# 按列剔除 print(df.dropna(axis=1)) print() # 如果某列有缺失值,则删除这一行 print(df.dropna(subset=['B'])) print() A 0 1 1 A 2 7 A B C 0 1 2.0 <NA> 2 7 8.0 9# 填充缺失值 df = pd.read_csv('static/2_pandas/data/weather_withna.csv') print(df.isna().sum()) date 0 precipitation 303 temp_max 303 temp_min 303 wind 303 weather 303 dtype: int64# 使用字典填充 print(df.fillna({"temp_max": 100, "wind": 20}).tail()) date precipitation temp_max temp_min wind weather 1456 2015-12-27 NaN 100.0 NaN 20.0 NaN 1457 2015-12-28 NaN 100.0 NaN 20.0 NaN 1458 2015-12-29 NaN 100.0 NaN 20.0 NaN 1459 2015-12-30 NaN 100.0 NaN 20.0 NaN 1460 2015-12-31 20.6 12.2 5.0 3.8 rain# 使用统计值填充 print(df.fillna(df[['temp_max', 'wind']].mean()).tail()) date precipitation temp_max temp_min wind weather 1456 2015-12-27 NaN 15.851468 NaN 3.242055 NaN 1457 2015-12-28 NaN 15.851468 NaN 3.242055 NaN 1458 2015-12-29 NaN 15.851468 NaN 3.242055 NaN 1459 2015-12-30 NaN 15.851468 NaN 3.242055 NaN 1460 2015-12-31 20.6 12.200000 5.0 3.800000 rain# 根据附近的值填充 front print(df.ffill().tail()) print() # 根据附近的值填充 behind print(df.bfill().tail()) date precipitation temp_max temp_min wind weather 1456 2015-12-27 0.0 11.1 4.4 4.8 sun 1457 2015-12-28 0.0 11.1 4.4 4.8 sun 1458 2015-12-29 0.0 11.1 4.4 4.8 sun 1459 2015-12-30 0.0 11.1 4.4 4.8 sun 1460 2015-12-31 20.6 12.2 5.0 3.8 rain date precipitation temp_max temp_min wind weather 1456 2015-12-27 20.6 12.2 5.0 3.8 rain 1457 2015-12-28 20.6 12.2 5.0 3.8 rain 1458 2015-12-29 20.6 12.2 5.0 3.8 rain 1459 2015-12-30 20.6 12.2 5.0 3.8 rain 1460 2015-12-31 20.6 12.2 5.0 3.8 rain3. 重复数据处理import pandas as pd data = { "name": ["孙笑川", "药水哥", "孙笑川", "刘波", "冬泳怪鸽", "刘波"], "age": [33, 30, 33, 30, 40, 30], "address": ["成都", "武汉", "成都", "武汉", "北京", "武汉"] } df = pd.DataFrame(data) print(df) name age address 0 孙笑川 33 成都 1 药水哥 30 武汉 2 孙笑川 33 成都 3 刘波 30 武汉 4 冬泳怪鸽 40 北京 5 刘波 30 武汉# 一整条记录都是重复的才标记 print(df.duplicated()) print() # 去重 # print(df.drop_duplicates()) # 根据指定列去重 print(df.drop_duplicates(subset=['address'])) print() # 根据指定列去重(保持最新的记录) print(df.drop_duplicates(subset=['address'], keep='last')) 0 False 1 False 2 True 3 False 4 False 5 True dtype: bool name age address 0 孙笑川 33 成都 1 药水哥 30 武汉 4 冬泳怪鸽 40 北京 name age address 2 孙笑川 33 成都 4 冬泳怪鸽 40 北京 5 刘波 30 武汉4. 数据类型的转换import pandas as pd df = pd.read_csv('static/2_pandas/data/sleep.csv') print(df) person_id gender age occupation sleep_duration sleep_quality \ 0 1 Male 29 Manual Labor 7.4 7.0 1 2 Female 43 Retired 4.2 4.9 2 3 Male 44 Retired 6.1 6.0 3 4 Male 29 Office Worker 8.3 10.0 4 5 Male 67 Retired 9.1 9.5 .. ... ... ... ... ... ... 395 396 Female 36 Student 4.5 7.9 396 397 Female 45 Manual Labor 6.0 6.1 397 398 Female 30 Student 5.3 6.5 398 399 Female 41 Retired 11.0 9.1 399 400 Male 37 Retired 5.8 7.0 physical_activity_level stress_level bmi_category blood_pressure \ 0 41 7 Obese 124/70 1 41 5 Obese 131/86 2 107 4 Underweight 122/70 3 20 10 Obese 124/72 4 19 4 Overweight 133/78 .. ... ... ... ... 395 73 7 Normal 118/66 396 72 8 Obese 132/80 397 58 10 Obese 125/76 398 73 9 Obese 130/75 399 41 6 Normal 118/70 heart_rate daily_steps sleep_disorder 0 91 8539 NaN 1 81 18754 NaN 2 81 2857 NaN 3 55 6886 NaN 4 97 14945 Insomnia .. ... ... ... 395 64 14497 Sleep Apnea 396 65 12848 Insomnia 397 66 15255 Insomnia 398 75 6567 Sleep Apnea 399 51 18079 NaN [400 rows x 13 columns]print(df.dtypes) person_id int64 gender object age int64 occupation object sleep_duration float64 sleep_quality float64 physical_activity_level int64 stress_level int64 bmi_category object blood_pressure object heart_rate int64 daily_steps int64 sleep_disorder object dtype: objectdf.age = df.age.astype('int16') print(df.dtypes) person_id int64 gender object age int16 occupation object sleep_duration float64 sleep_quality float64 physical_activity_level int64 stress_level int64 bmi_category object blood_pressure object heart_rate int64 daily_steps int64 sleep_disorder object dtype: objectdf.gender = df.gender.astype('category') print(df.dtypes) print() print(df.gender) person_id int64 gender category age int16 occupation object sleep_duration float64 sleep_quality float64 physical_activity_level int64 stress_level int64 bmi_category object blood_pressure object heart_rate int64 daily_steps int64 sleep_disorder object dtype: object 0 Male 1 Female 2 Male 3 Male 4 Male ... 395 Female 396 Female 397 Female 398 Female 399 Male Name: gender, Length: 400, dtype: category Categories (2, object): ['Female', 'Male']5. 数据变形import pandas as pd data = { "id": [1001, 1002], "name": ["孙笑川", "刘波"], "math": [99, 89], "english": [60, 95], } df = pd.DataFrame(data) print(df) id name math english 0 1001 孙笑川 99 60 1 1002 刘波 89 95# 行列转置 print(df.T) 0 1 id 1001 1002 name 孙笑川 刘波 math 99 89 english 60 95# 宽表转长表 """ 1001 孙笑川 math 99 1001 孙笑川 english 99 """ print(df) print() df1 = pd.melt(df, id_vars=['id', 'name'], var_name='科目', value_name='分数') print(df1) id name math english 0 1001 孙笑川 99 60 1 1002 刘波 89 95 id name 科目 分数 0 1001 孙笑川 math 99 1 1002 刘波 math 89 2 1001 孙笑川 english 60 3 1002 刘波 english 95# 长表转宽表 df2 = pd.pivot(df1, index=['id', 'name'], columns='科目', values='分数') print(df2) 科目 english math id name 1001 孙笑川 60 99 1002 刘波 95 89# 分列 data = { "id": [1001, 1002], "name": ["孙笑川 带带大师兄", "刘波 药水哥"], "math": [99, 89], "english": [60, 95], } df = pd.DataFrame(data) df[['first name', 'last name']] = df.name.str.split(" ", expand=True) print(df) id name math english first name last name 0 1001 孙笑川 带带大师兄 99 60 孙笑川 带带大师兄 1 1002 刘波 药水哥 89 95 刘波 药水哥df = pd.read_csv('static/2_pandas/data/sleep.csv') df = df[['person_id', 'blood_pressure']] print(df) print() df[['high_pressure', 'low_pressure']] = df['blood_pressure'].str.split("/", expand=True) df.high_pressure = df.high_pressure.astype('int16') df.low_pressure = df.low_pressure.astype('int16') print(df) print() df.info() person_id blood_pressure 0 1 124/70 1 2 131/86 2 3 122/70 3 4 124/72 4 5 133/78 .. ... ... 395 396 118/66 396 397 132/80 397 398 125/76 398 399 130/75 399 400 118/70 [400 rows x 2 columns] person_id blood_pressure high_pressure low_pressure 0 1 124/70 124 70 1 2 131/86 131 86 2 3 122/70 122 70 3 4 124/72 124 72 4 5 133/78 133 78 .. ... ... ... ... 395 396 118/66 118 66 396 397 132/80 132 80 397 398 125/76 125 76 398 399 130/75 130 75 399 400 118/70 118 70 [400 rows x 4 columns] <class 'pandas.core.frame.DataFrame'> RangeIndex: 400 entries, 0 to 399 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 person_id 400 non-null int64 1 blood_pressure 400 non-null object 2 high_pressure 400 non-null int16 3 low_pressure 400 non-null int16 dtypes: int16(2), int64(1), object(1) memory usage: 7.9+ KB6. 数据分箱import pandas as pd df = pd.read_csv('static/2_pandas/data/employees.csv') print(df.head(10)) employee_id first_name last_name email phone_number job_id \ 0 100 Steven King SKING 515.123.4567 AD_PRES 1 101 N_ann Kochhar NKOCHHAR 515.123.4568 AD_VP 2 102 Lex De Haan LDEHAAN 515.123.4569 AD_VP 3 103 Alexander Hunold AHUNOLD 590.423.4567 IT_PROG 4 104 Bruce Ernst BERNST 590.423.4568 IT_PROG 5 105 David Austin DAUSTIN 590.423.4569 IT_PROG 6 106 Valli Pataballa VPATABAL 590.423.4560 IT_PROG 7 107 Diana Lorentz DLORENTZ 590.423.5567 IT_PROG 8 108 Nancy Greenberg NGREENBE 515.124.4569 FI_MGR 9 109 Daniel Faviet DFAVIET 515.124.4169 FI_ACCOUNT salary commission_pct manager_id department_id 0 24000.0 NaN NaN 90.0 1 17000.0 NaN 100.0 90.0 2 17000.0 NaN 100.0 90.0 3 9000.0 NaN 102.0 60.0 4 6000.0 NaN 103.0 60.0 5 4800.0 NaN 103.0 60.0 6 4800.0 NaN 103.0 60.0 7 4200.0 NaN 103.0 60.0 8 12000.0 NaN 101.0 100.0 9 9000.0 NaN 108.0 100.0 df1 = df.head(10)[['employee_id', 'salary']] print(df1) print() # pd.cut() # bins=n 分成n段区间,起始值,结束值是所有数据中的最小值、最大值 print(pd.cut(df1['salary'], bins=2)) print() # bins=[] 自定义区间的值 df1_cut = pd.cut(df1['salary'], bins=[0, 5000, 10000, 20000]) print(df1_cut) print() df1_cut['收入范围'] = pd.cut(df1['salary'], bins=[0, 5000, 10000, 20000], labels=['低', '中', '高']) print(df1_cut) print() # 等分为指定的段数 df1_qcut = pd.qcut(df1['salary'], 3) print(df1_qcut) employee_id salary 0 100 24000.0 1 101 17000.0 2 102 17000.0 3 103 9000.0 4 104 6000.0 5 105 4800.0 6 106 4800.0 7 107 4200.0 8 108 12000.0 9 109 9000.0 0 (14100.0, 24000.0] 1 (14100.0, 24000.0] 2 (14100.0, 24000.0] 3 (4180.2, 14100.0] 4 (4180.2, 14100.0] 5 (4180.2, 14100.0] 6 (4180.2, 14100.0] 7 (4180.2, 14100.0] 8 (4180.2, 14100.0] 9 (4180.2, 14100.0] Name: salary, dtype: category Categories (2, interval[float64, right]): [(4180.2, 14100.0] < (14100.0, 24000.0]] 0 NaN 1 (10000.0, 20000.0] 2 (10000.0, 20000.0] 3 (5000.0, 10000.0] 4 (5000.0, 10000.0] 5 (0.0, 5000.0] 6 (0.0, 5000.0] 7 (0.0, 5000.0] 8 (10000.0, 20000.0] 9 (5000.0, 10000.0] Name: salary, dtype: category Categories (3, interval[int64, right]): [(0, 5000] < (5000, 10000] < (10000, 20000]] 0 NaN 1 (10000, 20000] 2 (10000, 20000] 3 (5000, 10000] 4 (5000, 10000] 5 (0, 5000] 6 (0, 5000] 7 (0, 5000] 8 (10000, 20000] 9 (5000, 10000] 收入范围 0 NaN 1 高 2 高 3 中 4 中 5... Name: salary, dtype: object 0 (12000.0, 24000.0] 1 (12000.0, 24000.0] 2 (12000.0, 24000.0] 3 (6000.0, 12000.0] 4 (6000.0, 12000.0] 5 (4199.999, 6000.0] 6 (4199.999, 6000.0] 7 (4199.999, 6000.0] 8 (12000.0, 24000.0] 9 (6000.0, 12000.0] Name: salary, dtype: category Categories (3, interval[float64, right]): [(4199.999, 6000.0] < (6000.0, 12000.0] < (12000.0, 24000.0]]df = pd.read_csv('static/2_pandas/data/sleep.csv') df1 = df.head(10)[['person_id', 'sleep_quality']] # 源数据 ---> 分箱 ---> 统计 df1['睡眠质量'] = pd.cut(df1['sleep_quality'], bins=3, labels=['差', '良好', '优秀']) print(df1['睡眠质量'].value_counts()) 睡眠质量 良好 5 差 3 优秀 2 Name: count, dtype: int64# df.rename() df = pd.DataFrame({ "name": ["孙笑川", "药水哥", "刘波", "冬泳怪鸽"], "age": [33, 30, 40, 30], "address": ["成都", "武汉", "武汉", "北京"] }) print(df) print() print(df.rename(index={0: 5}, columns={"address": "地址"})) name age address 0 孙笑川 33 成都 1 药水哥 30 武汉 2 刘波 40 武汉 3 冬泳怪鸽 30 北京 name age 地址 5 孙笑川 33 成都 1 药水哥 30 武汉 2 刘波 40 武汉 3 冬泳怪鸽 30 北京# df.set_index() # inplace=True 在原数据上修改 df.set_index('name', inplace=True) print(df) age address name 孙笑川 33 成都 药水哥 30 武汉 刘波 40 武汉 冬泳怪鸽 30 北京# df.reset_index() df.reset_index(inplace=True) print(df) name age address 0 孙笑川 33 成都 1 药水哥 30 武汉 2 刘波 40 武汉 3 冬泳怪鸽 30 北京7. 时间数据的处理import pandas as pd d = pd.Timestamp('2025-12-03 14:58') print(d) print(type(d)) 2025-12-03 14:58:00 <class 'pandas._libs.tslibs.timestamps.Timestamp'># 属性 print("年:", d.year) print("月:", d.month) print("日:", d.day) print("时间:", d.hour, d.minute, d.second) print("是否为当月的最后一天:", d.is_month_end) 年: 2025 月: 12 日: 3 时间: 14 58 0 是否为当月的最后一天: False# 方法 print("周几:", d.day_name()) print("转换为日期(天):", d.to_period('D')) 周几: Wednesday 转换为日期(天): 2025-12-03# 字符串转换为日期类型 d = pd.to_datetime('2025-12-03 14:58') print(d) print(type(d)) 2025-12-03 14:58:00 <class 'pandas._libs.tslibs.timestamps.Timestamp'>df = pd.DataFrame({ "id": [1001, 1002], "name": ["孙笑川", "药水哥"], "date_str": ["20251201", "20251202"] }) print(df) print() df['create_time'] = pd.to_datetime(df['date_str']) print(df) print() df['week'] = df['create_time'].dt.day_name() print(df) id name date_str 0 1001 孙笑川 20251201 1 1002 药水哥 20251202 id name date_str create_time 0 1001 孙笑川 20251201 2025-12-01 1 1002 药水哥 20251202 2025-12-02 id name date_str create_time week 0 1001 孙笑川 20251201 2025-12-01 Monday 1 1002 药水哥 20251202 2025-12-02 Tuesday# csv中的日期转换 df = pd.read_csv('static/2_pandas/data/weather.csv') df['datetime'] = pd.to_datetime(df['date']) print(df.head(10)) print() # 读取csv时同步进行转换 df = pd.read_csv('static/2_pandas/data/weather.csv', parse_dates=['date']) print(df['date'].dtypes) date precipitation temp_max temp_min wind weather datetime 0 2012-01-01 0.0 12.8 5.0 4.7 drizzle 2012-01-01 1 2012-01-02 10.9 10.6 2.8 4.5 rain 2012-01-02 2 2012-01-03 0.8 11.7 7.2 2.3 rain 2012-01-03 3 2012-01-04 20.3 12.2 5.6 4.7 rain 2012-01-04 4 2012-01-05 1.3 8.9 2.8 6.1 rain 2012-01-05 5 2012-01-06 2.5 4.4 2.2 2.2 rain 2012-01-06 6 2012-01-07 0.0 7.2 2.8 2.3 rain 2012-01-07 7 2012-01-08 0.0 10.0 2.8 2.0 sun 2012-01-08 8 2012-01-09 4.3 9.4 5.0 3.4 rain 2012-01-09 9 2012-01-10 1.0 6.1 0.6 3.4 rain 2012-01-10 datetime64[ns]# 日期数据作为索引 df1 = df.set_index('date') print(df1) print() precipitation temp_max temp_min wind weather date 2012-01-01 0.0 12.8 5.0 4.7 drizzle 2012-01-02 10.9 10.6 2.8 4.5 rain 2012-01-03 0.8 11.7 7.2 2.3 rain 2012-01-04 20.3 12.2 5.6 4.7 rain 2012-01-05 1.3 8.9 2.8 6.1 rain ... ... ... ... ... ... 2015-12-27 8.6 4.4 1.7 2.9 rain 2015-12-28 1.5 5.0 1.7 1.3 rain 2015-12-29 0.0 7.2 0.6 2.6 fog 2015-12-30 0.0 5.6 -1.0 3.4 sun 2015-12-31 0.0 5.6 -2.1 3.5 sun [1461 rows x 5 columns]# 时间间隔 d1 = pd.Timestamp('2020-01-10') d2 = pd.Timestamp('2020-03-05') print(d2-d1) 55 days 00:00:00# 按时间维度重采样 df = pd.read_csv('static/2_pandas/data/weather.csv', parse_dates=['date']) df.set_index('date', inplace=True) print(df[['temp_max', 'temp_min']].resample("YE").mean()) temp_max temp_min date 2012-12-31 15.276776 7.289617 2013-12-31 16.058904 8.153973 2014-12-31 16.995890 8.662466 2015-12-31 17.427945 8.8356168. 分组聚合# df.groupby('分组的字段')['聚合的字段'].聚合函数 import pandas as pd df = pd.read_csv('static/2_pandas/data/employees.csv') print(df.head(10)) employee_id first_name last_name email phone_number job_id \ 0 100 Steven King SKING 515.123.4567 AD_PRES 1 101 N_ann Kochhar NKOCHHAR 515.123.4568 AD_VP 2 102 Lex De Haan LDEHAAN 515.123.4569 AD_VP 3 103 Alexander Hunold AHUNOLD 590.423.4567 IT_PROG 4 104 Bruce Ernst BERNST 590.423.4568 IT_PROG 5 105 David Austin DAUSTIN 590.423.4569 IT_PROG 6 106 Valli Pataballa VPATABAL 590.423.4560 IT_PROG 7 107 Diana Lorentz DLORENTZ 590.423.5567 IT_PROG 8 108 Nancy Greenberg NGREENBE 515.124.4569 FI_MGR 9 109 Daniel Faviet DFAVIET 515.124.4169 FI_ACCOUNT salary commission_pct manager_id department_id 0 24000.0 NaN NaN 90.0 1 17000.0 NaN 100.0 90.0 2 17000.0 NaN 100.0 90.0 3 9000.0 NaN 102.0 60.0 4 6000.0 NaN 103.0 60.0 5 4800.0 NaN 103.0 60.0 6 4800.0 NaN 103.0 60.0 7 4200.0 NaN 103.0 60.0 8 12000.0 NaN 101.0 100.0 9 9000.0 NaN 108.0 100.0 # 缺失值处理 df = df.dropna(subset=['department_id']) df['department_id'] = df['department_id'].astype('int64') print(df.head(10)) employee_id first_name last_name email phone_number job_id \ 0 100 Steven King SKING 515.123.4567 AD_PRES 1 101 N_ann Kochhar NKOCHHAR 515.123.4568 AD_VP 2 102 Lex De Haan LDEHAAN 515.123.4569 AD_VP 3 103 Alexander Hunold AHUNOLD 590.423.4567 IT_PROG 4 104 Bruce Ernst BERNST 590.423.4568 IT_PROG 5 105 David Austin DAUSTIN 590.423.4569 IT_PROG 6 106 Valli Pataballa VPATABAL 590.423.4560 IT_PROG 7 107 Diana Lorentz DLORENTZ 590.423.5567 IT_PROG 8 108 Nancy Greenberg NGREENBE 515.124.4569 FI_MGR 9 109 Daniel Faviet DFAVIET 515.124.4169 FI_ACCOUNT salary commission_pct manager_id department_id 0 24000.0 NaN NaN 90 1 17000.0 NaN 100.0 90 2 17000.0 NaN 100.0 90 3 9000.0 NaN 102.0 60 4 6000.0 NaN 103.0 60 5 4800.0 NaN 103.0 60 6 4800.0 NaN 103.0 60 7 4200.0 NaN 103.0 60 8 12000.0 NaN 101.0 100 9 9000.0 NaN 108.0 100 # 计算不同部门的平均薪资 # .groups 查看分组 print(df.groupby('department_id').groups) print() # get_group() 查看具体的分组数据 print(df.groupby('department_id').get_group(20)) {10: [100], 20: [101, 102], 30: [14, 15, 16, 17, 18, 19], 40: [103], 50: [20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99], 60: [3, 4, 5, 6, 7], 70: [104], 80: [45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 79], 90: [0, 1, 2], 100: [8, 9, 10, 11, 12, 13], 110: [105, 106]} employee_id first_name last_name email phone_number job_id \ 101 201 Michael Hartstein MHARTSTE 515.123.5555 MK_MAN 102 202 Pat Fay PFAY 603.123.6666 MK_REP salary commission_pct manager_id department_id 101 13000.0 NaN 100.0 20 102 6000.0 NaN 201.0 20 df1 = df.groupby('department_id')[['salary']].mean() df1['salary'] = df1['salary'].round(2) df1.reset_index(inplace=True) print(df1.sort_values('salary', ascending=False)) department_id salary 8 90 19333.33 10 110 10150.00 6 70 10000.00 1 20 9500.00 7 80 8955.88 9 100 8600.00 3 40 6500.00 5 60 5760.00 0 10 4400.00 2 30 4150.00 4 50 3475.56# 按部门、岗位分组聚合 df2 = df.groupby(['department_id', 'job_id'])[['salary']].mean() df2['salary'] = df2['salary'].round(2) df2.reset_index(inplace=True) print(df2.sort_values('salary', ascending=False)) department_id job_id salary 13 90 AD_PRES 24000.00 14 90 AD_VP 17000.00 1 20 MK_MAN 13000.00 11 80 SA_MAN 12200.00 16 100 FI_MGR 12000.00 18 110 AC_MGR 12000.00 4 30 PU_MAN 11000.00 10 70 PR_REP 10000.00 12 80 SA_REP 8396.55 17 110 AC_ACCOUNT 8300.00 15 100 FI_ACCOUNT 7920.00 8 50 ST_MAN 7280.00 5 40 HR_REP 6500.00 2 20 MK_REP 6000.00 9 60 IT_PROG 5760.00 0 10 AD_ASST 4400.00 6 50 SH_CLERK 3215.00 7 50 ST_CLERK 2785.00 3 30 PU_CLERK 2780.00
-
五、pandas-DataFrame-案例 (1)学生成绩分析某班级的学生成绩如下:姓名语文数学英语孙笑川909565药水哥919670Giao哥808990刘波7588951.计算每名学生的总分和平均分2.找出数学成绩高于90分或英语成绩高于85分的学生3.按总分降序排序(显示前三名)import numpy as np import pandas as pd data = { "姓名": ["孙笑川", "药水哥", "Giao哥", "刘波"], "语文": [90, 91, 80, 75], "数学": [95, 96, 89, 88], "英语": [65, 70, 90, 95] } scores = pd.DataFrame(data) print(scores) 姓名 语文 数学 英语 0 孙笑川 90 95 65 1 药水哥 91 96 70 2 Giao哥 80 89 90 3 刘波 75 88 95scores['总分'] = scores[['语文', '数学', '英语']].sum(axis=1) print(scores) print("================================================") # scores['平均分'] = scores['总分'] / 3 scores['平均分'] = scores[['语文', '数学', '英语']].mean(axis=1) print(scores) 姓名 语文 数学 英语 总分 0 孙笑川 90 95 65 250 1 药水哥 91 96 70 257 2 Giao哥 80 89 90 259 3 刘波 75 88 95 258 ================================================ 姓名 语文 数学 英语 总分 平均分 0 孙笑川 90 95 65 250 83.333333 1 药水哥 91 96 70 257 85.666667 2 Giao哥 80 89 90 259 86.333333 3 刘波 75 88 95 258 86.000000print(scores[(scores['数学'] > 90) | (scores['英语'] > 85)]) 姓名 语文 数学 英语 总分 平均分 0 孙笑川 90 95 65 250 83.333333 1 药水哥 91 96 70 257 85.666667 2 Giao哥 80 89 90 259 86.333333 3 刘波 75 88 95 258 86.000000# print(scores.sort_values('总分', ascending=False).head(3)) print(scores.nlargest(3, columns='总分')) 姓名 语文 数学 英语 总分 平均分 2 Giao哥 80 89 90 259 86.333333 3 刘波 75 88 95 258 86.000000 1 药水哥 91 96 70 257 85.666667(2)销售数据分析某公司销售数据如下:产品名称苹果西瓜葡萄梨单价(斤/元)8.53.5105.5销量(斤)5010020300计算每种产品的总销售额2.找出销售额最高的商品3.按销售额降序排序import numpy as np import pandas as pd data = { "产品名称": ["苹果", "西瓜", "葡萄", "梨"], "单价(斤/元)": [8.5, 3.5, 10, 5.5], "销量(斤)": [50, 100, 20, 300] } df = pd.DataFrame(data) print(df) 产品名称 单价(斤/元) 销量(斤) 0 苹果 8.5 50 1 西瓜 3.5 100 2 葡萄 10.0 20 3 梨 5.5 300df['总销售额'] = df['单价(斤/元)'] * df['销量(斤)'] print(df) 产品名称 单价(斤/元) 销量(斤) 总销售额 0 苹果 8.5 50 425.0 1 西瓜 3.5 100 350.0 2 葡萄 10.0 20 200.0 3 梨 5.5 300 1650.0print(df.nlargest(1, columns='总销售额')) 产品名称 单价(斤/元) 销量(斤) 总销售额 3 梨 5.5 300 1650.0print(df.sort_values('总销售额', ascending=False)) 产品名称 单价(斤/元) 销量(斤) 总销售额 3 梨 5.5 300 1650.0 0 苹果 8.5 50 425.0 1 西瓜 3.5 100 350.0 2 葡萄 10.0 20 200.0(3)电商用户行为分析某电商平台的用户行为数据如下:用户ID用户名商品类别商品单价购买数量1孙笑川电子产品300052药水哥服装200103Giao哥电子产品500054刘波日用50020 冬泳怪鸽五金30151.计算每位用户的总消费金额2.找出消费金额最高的用户3.计算用户的平均消费金额(保留两位小数)4.统计电子产品的总购买数量import numpy as np import pandas as pd data = { "用户ID": [1, 2, 3, 4, 5], "用户名": ["孙笑川", "药水哥", "Giao哥", "刘波", "冬泳怪鸽"], "商品类别": ["电子产品", "服装", "电子产品", "日用", "五金"], "商品单价": [3000, 200, 5000, 500, 30], "购买数量": [5, 10, 5, 20, 15], } df = pd.DataFrame(data) print(df) 用户ID 用户名 商品类别 商品单价 购买数量 0 1 孙笑川 电子产品 3000 5 1 2 药水哥 服装 200 10 2 3 Giao哥 电子产品 5000 5 3 4 刘波 日用 500 20 4 5 冬泳怪鸽 五金 30 15df['总消费金额'] = df['商品单价'] * df['购买数量'] print(df) 用户ID 用户名 商品类别 商品单价 购买数量 总消费金额 0 1 孙笑川 电子产品 3000 5 15000 1 2 药水哥 服装 200 10 2000 2 3 Giao哥 电子产品 5000 5 25000 3 4 刘波 日用 500 20 10000 4 5 冬泳怪鸽 五金 30 15 450print(df.nlargest(1, columns='总消费金额')) 用户ID 用户名 商品类别 商品单价 购买数量 总消费金额 2 3 Giao哥 电子产品 5000 5 25000cost = df['总消费金额'].mean() print(cost) 10490.0print(df[df['商品类别'] == '电子产品']['购买数量'].sum()) 10
-
四、pandas - DataFrame 1. 创建方法import numpy as np import pandas as pd # 通过Series创建 s1 = pd.Series([1, 2, 3]) s2 = pd.Series([4, 5, 6]) df = pd.DataFrame({"1": s1, "2": s2}) print(df) 1 2 0 1 4 1 2 5 2 3 6# 通过字典创建 # 可以通过columns属性指定列的顺序 df = pd.DataFrame( { "id": [1, 2, 3], "name": ["孙笑川", "药水哥", "Giao哥"], "age": [33, 30, 33] } ) print(df) id name age 0 1 孙笑川 33 1 2 药水哥 30 2 3 Giao哥 332. 属性属性说明index行索引values值dtypes元素类型shape形状ndim维度size元素个数columns列标签loc[]显示索引,按行列标签索引或切片iloc[]隐式索引,按行列位置索引或切片at[]使用行列标签访问指定元素iat[]使用行列位置访问指定元素T行列转置print("行索引:", df.index) print("列标签", df.columns) print("值:", df.values) 行索引: RangeIndex(start=0, stop=3, step=1) 列标签 Index(['id', 'name', 'age'], dtype='object') 值: [[1 '孙笑川' 33] [2 '药水哥' 30] [3 'Giao哥' 33]]print("形状:", df.shape) print("维度:", df.ndim) print("数据类型:") print(df.dtypes) 形状: (3, 3) 维度: 2 数据类型: id int64 name object age int64 dtype: object# 行数据 # loc print(df.loc[1]) print("==================") # iloc print(df.iloc[1]) id 2 name 药水哥 age 30 Name: 1, dtype: object ================== id 2 name 药水哥 age 30 Name: 1, dtype: object# 列数据 print(df.loc[:, 'name']) print("==================") print(df.iloc[:, 1]) 0 孙笑川 1 药水哥 2 Giao哥 Name: name, dtype: object ================== 0 孙笑川 1 药水哥 2 Giao哥 Name: name, dtype: object# 获取指定元素 print(df.at[0, 'name']) print("==================") print(df.iat[0, 1]) print("==================") print(df.loc[0, 'name']) print("==================") print(df.iloc[0, 1]) 孙笑川 ================== 孙笑川 ================== 孙笑川 ================== 孙笑川# 行列转置 #print(df.T)# 获取单列数据 print(df['name']) print("==================") print(df.name) print("==================") column = df[['name']] print(column) print(type(column)) 0 孙笑川 1 药水哥 2 Giao哥 Name: name, dtype: object ================== 0 孙笑川 1 药水哥 2 Giao哥 Name: name, dtype: object ================== name 0 孙笑川 1 药水哥 2 Giao哥 <class 'pandas.core.frame.DataFrame'># 多列数据 print(df[['name', 'age']]) name age 0 孙笑川 33 1 药水哥 30 2 Giao哥 33# 获取部分数据 print(df.head(2)) print("==================") print(df.tail(2)) id name age 0 1 孙笑川 33 1 2 药水哥 30 ================== id name age 1 2 药水哥 30 2 3 Giao哥 33# 布尔索引 print(df[df.age > 32]) print("==================") print(df[(df.age > 32) & (df.id == 1)]) id name age 0 1 孙笑川 33 2 3 Giao哥 33 ================== id name age 0 1 孙笑川 33# 随机抽样 print(df.sample(2)) id name age 0 1 孙笑川 33 2 3 Giao哥 333. 常用方法方法说明head()获取前n行数据,默认值5tail()获取后n行数据,默认值5isin()判断元素是否包含在参数集合中isna()判断每一个元素是否为缺失值(NaN/None)sum()求和,自动忽略缺失值mean()平均值min()最小值max()最大值var()方差std()标准差median()中位数mode()众数(可以有多个返回值)quantile(q)分位数,q取值范围为:0~1describe()常见统计信息(count、mean、std、min、25%、50%、75%、max)value_counts()每个唯一值的出现次数count()非缺失值数量duplicated()是否重复drop_duplicates()去除重复项sample()随机抽样replace()替换sort_index()按索引排序sort_values()按值排序nlargest()返回某列最大的n条数据nsmallest()返回某列最小的n条数据df = pd.DataFrame( { "id": [1, 2, 3], "name": ["孙笑川", "药水哥", "Giao哥"], "age": [33, 30, 31], "address": ["成都", "武汉", "河南"] } ) print(df) id name age address 0 1 孙笑川 33 成都 1 2 药水哥 30 武汉 2 3 Giao哥 31 河南print(df.head(1)) print("============================") print(df.tail(1)) id name age address 0 1 孙笑川 33 成都 ============================ id name age address 2 3 Giao哥 31 河南# 查看元素是否包含在参数集合中 print(df.isin(["药水哥", 31])) id name age address 0 False False False False 1 False True False False 2 False False True False# 查看元素是否是缺失值 print(df.isna()) id name age address 0 False False False False 1 False False False False 2 False False False False# 求和 print(df.sum()) print("============================") print(df.age.sum()) id 6 name 孙笑川药水哥Giao哥 age 94 address 成都武汉河南 dtype: object ============================ 94# 最值 print(df.age.max()) print(df.name.min()) 33 Giao哥# 平均数 print(df.age.mean()) # 中位数 print(df.age.median()) # 众数 print(df.age.mode()) 31.333333333333332 31.0 0 30 1 31 2 33 Name: age, dtype: int64# 标准差 print(df.age.std()) # 方差 print(df.age.var()) # 分位数 print(df.age.quantile(0.25)) 1.5275252316519468 2.3333333333333335 30.5# 描述信息 print(df.describe()) id age count 3.0 3.000000 mean 2.0 31.333333 std 1.0 1.527525 min 1.0 30.000000 25% 1.5 30.500000 50% 2.0 31.000000 75% 2.5 32.000000 max 3.0 33.000000# 每一列中非缺失值的个数 print(df.count()) id 3 name 3 age 3 address 3 dtype: int64# 每一个唯一值的出现次数 print(df.value_counts()) id name age address 1 孙笑川 33 成都 1 2 药水哥 30 武汉 1 3 Giao哥 31 河南 1 Name: count, dtype: int64# 去重 print(df.drop_duplicates()) id name age address 0 1 孙笑川 33 成都 1 2 药水哥 30 武汉 2 3 Giao哥 31 河南# 判重 print(df.duplicated()) print("============================") # 指定列判重 print(df.duplicated(subset="name")) 0 False 1 False 2 False dtype: bool ============================ 0 False 1 False 2 False dtype: bool# 随机抽样 print(df.sample()) id name age address 2 3 Giao哥 31 河南# replace print(df.replace(30, 35)) id name age address 0 1 孙笑川 33 成都 1 2 药水哥 35 武汉 2 3 Giao哥 31 河南# 累计和 print(df.cumsum()) print("============================") # 参数 axis 0:按列累计,1按行累计 # 注:累计时需确保元素类型一直 print(df.cummax(axis=0)) id name age address 0 1 孙笑川 33 成都 1 3 孙笑川药水哥 63 成都武汉 2 6 孙笑川药水哥Giao哥 94 成都武汉河南 ============================ id name age address 0 1 孙笑川 33 成都 1 2 药水哥 33 武汉 2 3 药水哥 33 河南# 排序 print(df.sort_index()) print("============================") # 按值排序时需指定按哪一列排 print(df.sort_values(by='name')) print("============================") # 多列排序,并指定排序方式 False:倒序 True:升序 print(df.sort_values(by=['name', 'age'], ascending=[False, False])) id name age address 0 1 孙笑川 33 成都 1 2 药水哥 30 武汉 2 3 Giao哥 31 河南 ============================ id name age address 2 3 Giao哥 31 河南 0 1 孙笑川 33 成都 1 2 药水哥 30 武汉 ============================ id name age address 1 2 药水哥 30 武汉 0 1 孙笑川 33 成都 2 3 Giao哥 31 河南print(df.nlargest(2, columns=['age'])) print("============================") print(df.nsmallest(2, columns=['age'])) id name age address 0 1 孙笑川 33 成都 2 3 Giao哥 31 河南 ============================ id name age address 1 2 药水哥 30 武汉 2 3 Giao哥 31 河南
-
三、pandas-Series-案例 (1)学生成绩统计创建一个包含10名学生成绩的Series,成绩范围在50 - 100之间。计算平均分、最高分、最低分,并找出高于平均分的学生人数。import numpy as np import pandas as pd # 生成随机成绩 np.random.seed(1) scores = pd.Series(np.random.randint(50, 101, 10), index=['学生' + str(i) for i in range(1, 11)]) print(scores) 学生1 87 学生2 93 学生3 62 学生4 58 学生5 59 学生6 61 学生7 55 学生8 65 学生9 50 学生10 66 dtype: int32mean_score = scores.mean() print("平均分:", mean_score) print("最高分:", scores.max()) print("最低分:", scores.min()) print("成绩高于平均分的学生人数:", scores[scores > mean_score].count()) 平均分: 65.6 最高分: 93 最低分: 50 成绩高于平均分的学生人数: 3(2)温度数据分析给定某城市一周中每天的最高温度Series,计算温度超过30°的天数,平均温度,温度由高到低排序,并找出温度变化最大的两天import numpy as np import pandas as pd # 温度 temperature = pd.Series([28, 26, 33, 31, 32, 30, 27], index=['周一', '周二', '周三', '周四', '周五', '周六', '周日', ]) print(temperature) 周一 28 周二 26 周三 33 周四 31 周五 32 周六 30 周日 27 dtype: int64print("温度超过30°的天数:", temperature[temperature > 30].count()) print("平均温度:", round(temperature.mean(), 1)) # ascending=False 降序 temperature_sort = temperature.sort_values(ascending=False) print(temperature_sort) # 计算相邻两天的温度差值 temperature_diff = temperature.diff().abs() temperature_diff_sort = temperature_diff.sort_values(ascending=False) print("温度变化最大的两天:", temperature_diff_sort.index[:2].tolist()) 温度超过30°的天数: 3 平均温度: 29.6 周三 33 周五 32 周四 31 周六 30 周一 28 周日 27 周二 26 dtype: int64 温度变化最大的两天: ['周三', '周日'](3)股票价格分析给定某股票连续10个交易日的收盘价Series,计算每日收益率(当日收盘价/前日收盘价 - 1),找出收益率最高和最低的日期,计算波动率(收益率标准差)import numpy as np import pandas as pd prices = pd.Series([105.2, 103.1, 104.6, 102.9, 101.9, 106, 108.2, 105.1, 104.6, 102.9], index=pd.date_range('2025-10-01', periods=10)) print(prices) 2025-10-01 105.2 2025-10-02 103.1 2025-10-03 104.6 2025-10-04 102.9 2025-10-05 101.9 2025-10-06 106.0 2025-10-07 108.2 2025-10-08 105.1 2025-10-09 104.6 2025-10-10 102.9 Freq: D, dtype: float64print("收益率:") pct_change = prices.pct_change() print(pct_change) print("收益率最高的日期:", pct_change.idxmax()) print("收益率最低的日期:", pct_change.idxmin()) print("波动率:", pct_change.std()) 收益率: 2025-10-01 NaN 2025-10-02 -0.019962 2025-10-03 0.014549 2025-10-04 -0.016252 2025-10-05 -0.009718 2025-10-06 0.040236 2025-10-07 0.020755 2025-10-08 -0.028651 2025-10-09 -0.004757 2025-10-10 -0.016252 Freq: D, dtype: float64 收益率最高的日期: 2025-10-06 00:00:00 收益率最低的日期: 2025-10-08 00:00:00 波动率: 0.022586890620196715(4)销售数据分析某产品过去12个月的销售量Series,计算季度平均销量,销量最高的月份,月环比增长率,连续增长超过两个月的月份import numpy as np import pandas as pd sales = pd.Series([130, 135, 136, 131, 128, 130, 135, 137, 141, 135, 136, 133], index=pd.date_range('2024-02-01', periods=12, freq='ME')) print(sales) 2024-02-29 130 2024-03-31 135 2024-04-30 136 2024-05-31 131 2024-06-30 128 2024-07-31 130 2024-08-31 135 2024-09-30 137 2024-10-31 141 2024-11-30 135 2024-12-31 136 2025-01-31 133 Freq: ME, dtype: int64# resample() 重新采样 print("季度平均销量:") print(sales.resample("QE").mean()) 季度平均销量: 2024-03-31 132.500000 2024-06-30 131.666667 2024-09-30 134.000000 2024-12-31 137.333333 2025-03-31 133.000000 Freq: QE-DEC, dtype: float64print("销量最高的月份:", sales.idxmax()) 销量最高的月份: 2024-10-31 00:00:00print("月环比增长率:") sales_pct_change = sales.pct_change() print(sales_pct_change) 月环比增长率: 2024-02-29 NaN 2024-03-31 0.038462 2024-04-30 0.007407 2024-05-31 -0.036765 2024-06-30 -0.022901 2024-07-31 0.015625 2024-08-31 0.038462 2024-09-30 0.014815 2024-10-31 0.029197 2024-11-30 -0.042553 2024-12-31 0.007407 2025-01-31 -0.022059 Freq: ME, dtype: float64print("连续增长超过两个月的月份:") sales_up = sales_pct_change > 0 # rolling() 滑动窗口 rolling_up = sales_up.rolling(3).sum() == 3 print(sales_up[rolling_up].keys().tolist()) 连续增长超过两个月的月份: [Timestamp('2024-09-30 00:00:00'), Timestamp('2024-10-31 00:00:00')](5)每小时销售数据分析现有某商店每小时销售额Series,按天重采样计算每日的销售总额,计算每天营业时间(8:00 - 22:00)和非营业时间的销售额比例,找出销售额最高的三个小时import numpy as np import pandas as pd np.random.seed(1) hour_sales = pd.Series(np.random.randint(0, 100, 24), index=pd.date_range('2025-11-01', periods=24, freq='h')) print(hour_sales) 2025-11-01 00:00:00 37 2025-11-01 01:00:00 12 2025-11-01 02:00:00 72 2025-11-01 03:00:00 9 2025-11-01 04:00:00 75 2025-11-01 05:00:00 5 2025-11-01 06:00:00 79 2025-11-01 07:00:00 64 2025-11-01 08:00:00 16 2025-11-01 09:00:00 1 2025-11-01 10:00:00 76 2025-11-01 11:00:00 71 2025-11-01 12:00:00 6 2025-11-01 13:00:00 25 2025-11-01 14:00:00 50 2025-11-01 15:00:00 20 2025-11-01 16:00:00 18 2025-11-01 17:00:00 84 2025-11-01 18:00:00 11 2025-11-01 19:00:00 28 2025-11-01 20:00:00 29 2025-11-01 21:00:00 14 2025-11-01 22:00:00 50 2025-11-01 23:00:00 68 Freq: h, dtype: int32# 按天重采样 day_sales = hour_sales.resample('D').sum() print("当天销售总额:", day_sales) # print("当天销售总额:", hour_sales.sum()) 当天销售总额: 2025-11-01 920 Freq: D, dtype: int32# 营业时间的销售额 # business_hour_sales = hour_sales.between_time('8:00', '22:00') business_mask = (hour_sales.index.hour>=8) & (hour_sales.index.hour<=22) business_hour_sales = hour_sales[business_mask] business_sales = business_hour_sales.sum() # 非营业时间的销售额 # not_business_sales = day_sales - business_sales not_business_sales = hour_sales.drop(business_hour_sales.index).sum() print("营业时间与非营业时间销售额比例:") print(business_sales / not_business_sales) 营业时间与非营业时间销售额比例: 1.185273159144893print("销售额最高的三个小时:") #print(hour_sales.sort_values().tail(3)) print(hour_sales.nlargest(3)) 销售额最高的三个小时: 2025-11-01 17:00:00 84 2025-11-01 06:00:00 79 2025-11-01 10:00:00 76 dtype: int32
-
二、pandas - Series 1. 创建# 安装 pandas pip install pandasimport pandas as pd s = pd.Series([5, 1, 3, 2, 8, 10]) print(s) 0 5 1 1 2 3 3 2 4 8 5 10 dtype: int64# 自定义索引 s = pd.Series([5, 1, 3, 2, 8, 10], index=['A', 'B', 'C', 'D', 'E', 'F']) print(s) s = pd.Series([5, 1, 3, 2, 8, 10], index=[10, 20, 30, 40, 50, 60]) print(s) A 5 B 1 C 3 D 2 E 8 F 10 dtype: int64 10 5 20 1 30 3 40 2 50 8 60 10 dtype: int64# 自定义name(name用于描述这一列是干什么的) s = pd.Series([5, 1, 3, 2, 8, 10], index=[10, 20, 30, 40, 50, 60], name='成绩') print(s) 10 5 20 1 30 3 40 2 50 8 60 10 Name: 成绩, dtype: int64# 通过字典创建 s = pd.Series({'A': 10, 'B': 20, 'C': 30}) print(s) s1 = pd.Series(s, index=['A', 'C']) print(s1) A 10 B 20 C 30 dtype: int64 A 10 C 30 dtype: int642. 常用属性属性说明index索引(从0开始)values值dtype/dtypes元素的类型shape形状ndim维度size元素个数name名称loc[]显示索引,按标签索引或切片iloc[]隐式索引,按位置索引或切片at[]通过标签访问指定元素iat[]通过位置访问指定元素s = pd.Series([1, 2, 3, 4, 5], index=['A', 'B', 'C', 'D', 'E']) # index print(s.index) Index(['A', 'B', 'C', 'D', 'E'], dtype='object')# values print(s.values) [1 2 3 4 5]# shape ndim size print(s.shape, s.ndim, s.size) (5,) 1 5# name print(s.name) s.name = "测试" print(s.name) None 测试# loc[] 显示索引 print(s.loc['A']) # iloc[] 隐示索引 print(s.iloc[0]) # 同时也支持切片语法 print(s.loc['A':'C']) print(s.iloc[0:2]) 1 1 A 1 B 2 C 3 Name: 测试, dtype: int64 A 1 B 2 Name: 测试, dtype: int64# at 注:不支持切片语法 print(s.at['A']) # iat 注:不支持切片语法 print(s.iat[0]) 1 13. 访问数据的方式# 直接访问 # print(s[0]) 不建议这样使用,底层可能无法区分是取标签为0的值,还是取索引为0的值 print(s['A']) # 通过已设置的标签访问 1# 通过布尔索引访问 print(s[s<3]) A 1 B 2 Name: 测试, dtype: int64# head() 默认取前5行的数据 print(s.head()) s['F'] = 100 s['G'] = 200 print(s.head()) # tail() 默认取最后5行的数据 print(s.tail()) print("=======================") # 通过参数指定取几行的数据 print(s.head(2)) print("=======================") print(s.tail(3)) A 1 B 2 C 3 D 4 E 5 Name: 测试, dtype: int64 A 1 B 2 C 3 D 4 E 5 Name: 测试, dtype: int64 C 3 D 4 E 5 F 100 G 200 Name: 测试, dtype: int64 ======================= A 1 B 2 Name: 测试, dtype: int64 ======================= E 5 F 100 G 200 Name: 测试, dtype: int644. 常用方法方法说明head()查看前n行数据,默认值为5tail()查看后n行数据,默认值为5isin()判断集合中的每一个元素是否包含在指定的集合中isna()判断指定元素是否为缺失值(NaN/None)sum()求和(自动忽略缺失值)mean()平均值min()最小值max()最大值var()方差std()标准差median()中位数mode()众数(返回值可以有多个)quantile(q)分位数,q的取值范围:0 ~ 1describe()常见统计信息(如:count、mean、std、min、25%、50%、75%、max)value_count()每个唯一值出现的次数count()集合中非缺失值的数量nunique()唯一值个数(去重后的)unique()数组去重drop_duplicates()去除重复项,同理 unique()sample()随机抽样sort_index()按索引值排序sort_values()按值排序replace()替换keys()返回集合的索引s = pd.Series([5, 1, np.nan, 3, 2, None, 8]) s.name = 'datas' print(s) 0 5.0 1 1.0 2 NaN 3 3.0 4 2.0 5 NaN 6 8.0 Name: datas, dtype: float64# head() print(s.head()) 0 5.0 1 1.0 2 NaN 3 3.0 4 2.0 Name: datas, dtype: float64# tail() print(s.tail()) print("================") print(s.tail(1)) 2 NaN 3 3.0 4 2.0 5 NaN 6 8.0 Name: datas, dtype: float64 ================ 6 8.0 Name: datas, dtype: float64# 查看所有的描述信息 print(s.describe()) count 5.000000 mean 3.800000 std 2.774887 min 1.000000 25% 2.000000 50% 3.000000 75% 5.000000 max 8.000000 Name: datas, dtype: float64# 获取集合的元素个数(忽略缺失值) print(s.count()) 5# 获取集合的索引 print("通过方法获取:") print(s.keys()) print("通过属性获取:") print(s.index) 通过方法获取: RangeIndex(start=0, stop=7, step=1) 通过属性获取: RangeIndex(start=0, stop=7, step=1)# isna() 检查集合中的每一个元素是否为缺失值 print(s.isna()) 0 False 1 False 2 True 3 False 4 False 5 True 6 False Name: datas, dtype: bool# isin() print(s.isin([4, 5, 6])) 0 True 1 False 2 False 3 False 4 False 5 False 6 False Name: datas, dtype: bool# mean() print(s.mean()) # std() print(s.std()) # var() print(s.var()) # min() max() print(s.min()) print(s.max()) # median() print(s.median()) 3.8 2.7748873851023212 7.699999999999999 1.0 8.0 3.0""" |----|----|----|----| 1 2 3 5 8 去掉缺失值后等分4段(元素个数减一) quantile(0.25) 4 * 0.25 = 1 1在等分的第一段 分位数 = 1 + (2-1) * 1 = 2 """ print(s.sort_values()) print("===============") # quantile() print(s.quantile(0.25)) print(s.quantile(0.50)) print(s.quantile(0.75)) 1 1.0 4 2.0 3 3.0 0 5.0 6 8.0 2 NaN 5 NaN Name: datas, dtype: float64 =============== 2.0 3.0 5.0# mode() s[len(s)] = 1 print(s) print("===============") print(s.mode()) 0 5.0 1 1.0 2 NaN 3 3.0 4 2.0 5 NaN 6 8.0 7 1.0 Name: datas, dtype: float64 =============== 0 1.0 Name: datas, dtype: float64# 元素计数 print(s.value_counts()) datas 1.0 2 5.0 1 3.0 1 2.0 1 8.0 1 Name: count, dtype: int64# drop_duplicates() print(s) print("====================") print(s.drop_duplicates()) print("====================") s[len(s)] = 1 print(s.unique()) # 去重后的元素个数 print(s.nunique()) 0 5.0 1 1.0 2 NaN 3 3.0 4 2.0 5 NaN 6 8.0 7 1.0 Name: datas, dtype: float64 ==================== 0 5.0 1 1.0 2 NaN 3 3.0 4 2.0 6 8.0 Name: datas, dtype: float64 ==================== [ 5. 1. nan 3. 2. 8.] 5# sort_index() print(s.sort_index()) # sort_values() print(s.sort_values()) 0 5.0 1 1.0 2 NaN 3 3.0 4 2.0 5 NaN 6 8.0 7 1.0 8 1.0 Name: datas, dtype: float64 1 1.0 7 1.0 8 1.0 4 2.0 3 3.0 0 5.0 6 8.0 2 NaN 5 NaN Name: datas, dtype: float64
-
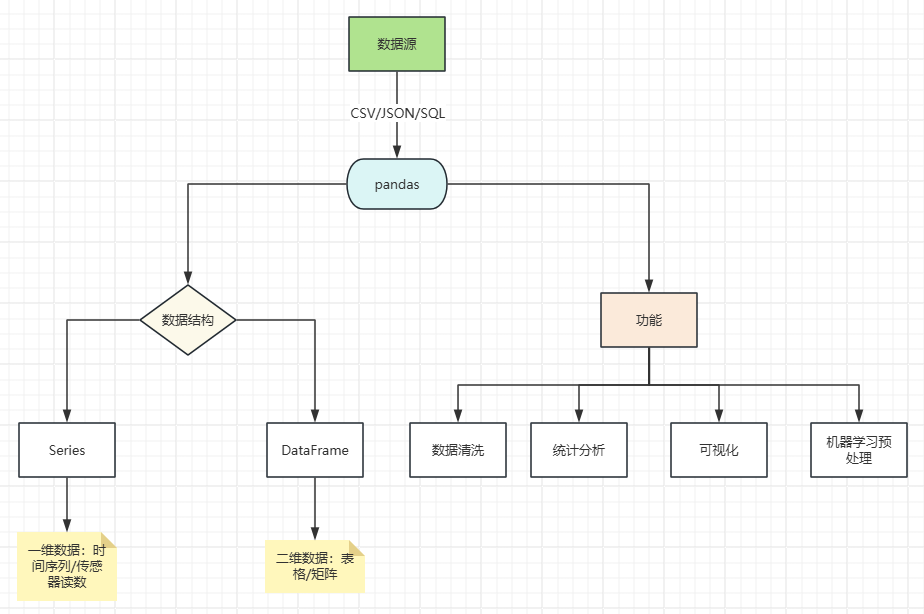
一、pandas 一、概要1. 简介pandas 是Python数据分析工具链中最核心的库,可用于数据读取、清洗、分析、统计、输出等,适用于处理结构化数据(如表格型数据)。2. 核心设计理念标签化数据结构:提供带标签的轴灵活处理缺失数据:内置NaN处理机制智能数据对齐:自动按标签对齐数据IO工具:支持CSV、Excel、SQL等多种数据源时间序列处理:原生支持日期时间处理和频率转换特性SeriesDataFrame维度一维二维索引单索引行索引 + 列名数据存储同质化数据类型各列的数据类型可以不同类比Excel 单列Excel Sheet创建方式pd.Series([1, 2, 3])pd.DataFrame({'col': [1, 2, 3]})